We are thrilled to announce that Prodigy v1.12.0 is out! This latest version marks a significant milestone for us, as it has been quite some time since our last big release. Thanks to everyone who helped us with testing the alpha versions!
For v1.12.0 we have completely refactored Prodigy internals to make the annotation flow more tractable and more customizable. We have re-built the Controller and added new abstractions for a better representation of the task stream and input source. This allowed us to deliver a number of really exciting features (and there's more to come!). We invite you to check out our documentation for the full changelog and extensive user guides on LLM integrations, task routing and deployment. We have also prepared a video tour of the highlights:

Here's a lineup of our favourite features with links to the brand new user guides:

Prodigy v1.12.0 introduces built-in recipes for jump-starting the annotation for Named Entity Recognition (NER) and Text Categorization (Textcat) using the OpenAI LLM service. These workflows enable annotators to efficiently curate label suggestions from a large language model which can significantly speed up the annotation process.
In addition to NER and Textcat, Prodigy v1.12.0 offers recipes for generating domain-specific terminologies. After the generated terms are curated, they can be utilized with the PatternMatcher, enabling another form of annotation bootstrapping.
The provided recipes support both zero-shot and few-shot prompts. This means you can supply a few examples of the expected output to guide model's prediction in the desired direction. While Prodigy includes a default prompt template, it also allows for custom templates tailored to your specific requirements.
To assist you in selecting the most effective prompt for your particular use case, Prodigy v1.12.0 includes prompt engineering recipes, aiding in the optimization of prompts for improved annotation outcomes.

You have the option to select A/B style evaluation for two or more prompts. We particularly recommend the ab.openai.tournament recipe that utilizes an algorithm influenced by the Glicko ranking system to arrange the duels and monitor the performance of the various prompts. For further information, please refer to our LLM guide.

We've exposed two brand new recipe components: the task router and the session factory . These components let you control how tasks are assigned to annotators and what should happen when a new annotator joins the server. In addition, we have expanded the annotation overlap settings. Apart from full and zero overlap, you can now set partial overlap via new annotations_per_task config setting.
More importantly, though you can implement a fully custom task router. For example, you could distribute tasks based on the model score or annotator's expertise. Please check out our guide to task routing for more details and ideas.
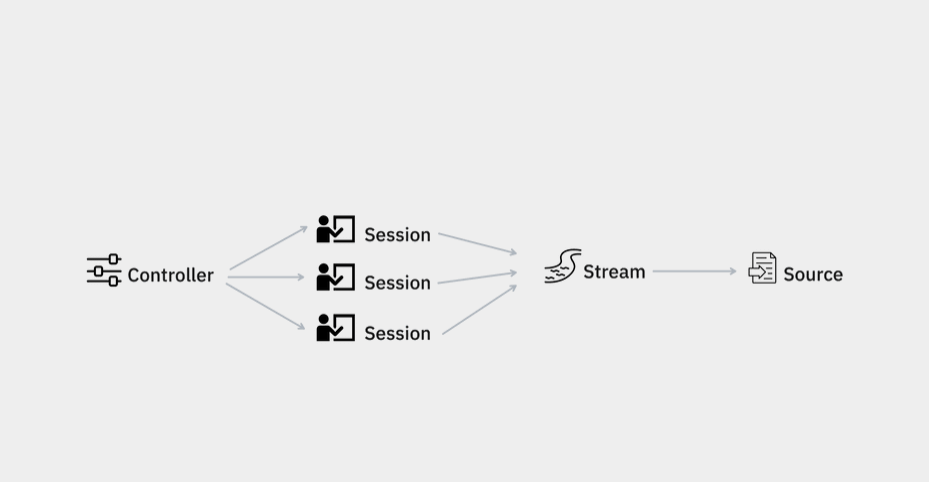
In Prodigy v1.12.0 we have re-implemented the internal representations of the task stream and the input source. The stream is now aware of the underlying source and how much of it has been consumed by the annotators.
This allows us to offer more reliable progress tracking for the workflows where the target number of annotations is not known upfront. In the UX, you'll notice 3 different types of progress bar: target progress (based on the set target), source progress (reflects the progress through the source object) and progress (for custom progress estimators). Since the semantics of these new progress bars is different, we recommend reading our docs on progress which explain that in detail.
We have also improved the loaders and provided a refactored get_stream utility that resolves the source type and initializes the Stream accordingly. We also added support for Parquet input files.
These are the highlights,v1.12.0 also comes with a number of smaller features, bug fixes and DX improvements. And it supports Python 3.11. Please check out the full v1.12.0 changelog for details.
As always, we are looking forward to any feedback you might have! This forum is a great place to share it ![]()
To install:
pip install --upgrade prodigy -f https://XXXX-XXXX-XXXX-XXXX@download.prodi.gy