Since releasing Prodigy in 2018, we've been blown away by its growth. We've sold over 3,000 personal licenses and nearly 800 company licenses. We're so grateful for your support and enthusiasm, it has been critical in supporting Explosion's growth as well. In 2021, we received our first round of funding, enabling us to grow our team to work on our biggest updates since Prodigy's release: Prodigy v1.12, v2.0, and Prodigy Teams.

Prodigy Teams
Let's start with Prodigy Teams. Many of you have asked about how to scale your Prodigy projects – including how to manage more annotators, keep multiple feeds running, make sure your annotators stay in agreement, and how to deploy Prodigy to the cloud. These are challenging problems that aren't in the design scope for Prodigy, so we've been working on a SaaS product called Prodigy Teams.
We're renaming Prodigy to Prodigy Local, a moniker for the core Prodigy product. You won't notice any difference, but this is to help distinguish it from Prodigy Teams.
Prodigy Local is designed as a developer tool to run on a local machine or internal server: the user installs the Python package, spins up the Prodigy server and annotates themselves, or exposes the app for annotators and sends them the link. While it's possible to host Prodigy Local in the cloud and manage multiple annotators, it's something the user has to set up themselves.
Deployment docs and your feedback to improve Prodigy
Deployment can be really hard. We've heard from users who have had challenges with deploying, especially to various cloud platforms without deep cloud or infra expertise. To help, we've created new docs with tips and patterns for deploying Prodigy Local to the cloud. Since every cloud platform has some unique features to their deployment stack the docs won't go over every deployment option out there. Instead, it will showcase some general patterns and will also mention some things to keep in mind as you deploy. But if you do have unique experiences or feedback about deployment or anything else, we'd love to hear from you in our Prodigy user survey!
We've pulled these features into Prodigy Teams, which follows a more classic "Software-as-a-Service" (SaaS) model.

Features introduced by Prodigy Teams include:
- prodigy in the cloud: web app is hosted on our servers, unique annotation URLs for every running task, and your data, and models are hosted on your private cluster
- user management: invite other developers and annotators to the application, and allow them to sign up for an account
- create and manage annotation tasks in the UI: use a form to set up and configure annotation tasks with different settings, view all running annotation tasks, assign users to different tasks, group tasks into projects
- import, export, and manage data: upload data to annotate, view collected annotations, download collected annotations
- run automated processes: use the collected annotations to regularly train new models and compare the accuracy, compute things like inter-annotator agreement, and perform other analytics on the data
- logging and auditing: see who accessed data and who annotated it for data security and legal compliance
Just like in Prodigy Local, data privacy, and scriptability are very important: the data should stay on the user's server and shouldn't have to be uploaded to or processed by ours. Users can implement custom workflows in Python, just like they can in Prodigy Local – we can't just provide them with pre-defined forms or run everything on our servers only. This introduces some novel challenges that make Prodigy Teams different from other similar SaaS applications.
But how could we build the same guarantee into Prodigy Teams, without making the app difficult to install and difficult to use? To solve this problem, we've split the application into different services. The service that reads your data runs entirely on your infrastructure, so your text, images, or other source data lives on your servers and you maintain access controls and admin permissions over their storage.
How do I sign up to be a beta tester for Prodigy Teams?
We owe a big thank you to the over 600+ responses who have previously signed up for beta testing! We're restarting Beta testing and reaching out to candidates on an individual basis in the upcoming weeks. We're fortunate to have a great pool of candidates already, but we'd still love to hear from you here if you're interested in being a beta tester.
How do I sign up to get Prodigy Teams?
Sign up to get on the Prodigy Teams waitlist.
Prodigy v1.12 and v2.0
Prodigy Local has been under intense development in the last few months as well. We've lined up a number of exciting features and improvements in our v1.12 release, its follow-ups, and our upcoming v2.0 release.

We refactored the core of Prodigy to provide better data validation across the application and enable full customization of the task stream. This is all in preparation for major front-end, database, and CLI improvements coming up in Prodigy v2.0 and within Prodigy Teams. But let's highlight what we're releasing in Prodigy v1.12.
Large language model (LLM) components
In July 2023, we released Prodigy 1.12 which included zero-shot and few-shot learning-assisted workflows through integration with OpenAI's API. Then in August 2023, we've released Prodigy v1.13 which integrates spacy-llm package so that users can now build their workflows with any hosted API. spacy-llm supports:
- closed-source models behind an API, like OpenAI's GPT-4 or Anthropic's Claude
- publicly-hosted OS models like Falcon and Dolly
- self-hosted models of any license type

We provide built-in recipes for the bootstrapping NER and Textcat annotations as well as generating terminology lists. Additionally, we provide built-in recipes for prompt engineering: A/B style evaluation for pairs of prompts and tournament style evaluation of several prompts. We invite you to check out the extensive guide to LLM workflows.
For more details on what's support, check out the spacy-llm docs or the Prodigy v1.13 section below with patch release posts.

As of v1.13, Prodigy provides a direct integration with OpenAI as well as an integration via
spacy-llm. You’re free to use whatever recipe you prefer for now, but OpenAI will deprecate some of the APIs that some of the*.openai.*recipes depend on in the near future. It’s not entirely clear when exactly this will happen, but you can learn more by reading this deprecation announcement.
Task routing and session factories:
task router and session factory are two brand-new components that allow for complete customization of the annotation flow. The task router determines how tasks should be distributed across annotators, while the session factory gives control over what should happen when a new session joins the annotation service.

We've provided some common-case defaults for both of these components. Apart from the known full or zero overlap, the user will now be able to specify the average number of annotations per example they are expected to get. More importantly though with these two components exposed any annotation protocol can be implemented. For example, tasks could be distributed based on the model score or the annotator's expertise. Please check out our guide to task routing for more details and ideas.
New Stream and Source classes
For Prodigy v1.12 we have refactored the internal representation of the stream of tasks and the underlying input source in a way that the stream object is aware of the source object, its type and how much of it has been consumed.
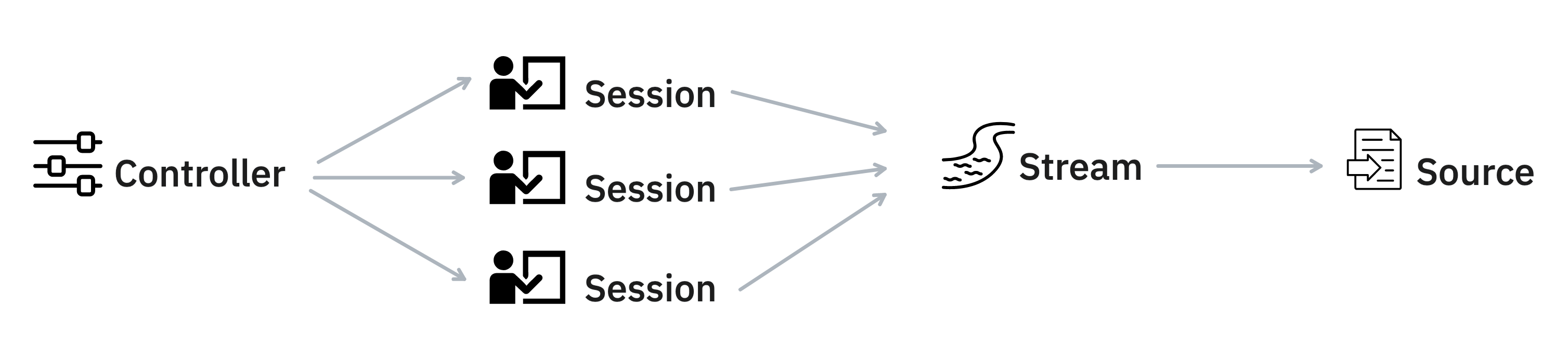
This allows us to provide more tractable progress tracking in projects where the target number of annotations is not known upfront. This was tricky when the stream was an opaque generator disconnected from the data source. In fact, we now distinguish between different types of progress in the front-end i.e. the progress (for custom functions), source progress (based on the progress through the input source) and the target progress (based on the set target). Since all these new progress bars have slightly different semantics be sure to check our docs on progress for extra context.
In 1.12, we've also made several other changes like:
- Python 3.11 support
- A new
filter_by_patternsrecipe - Experimental support for training
corefmodels - Parquet input files
- Documentation on Prodigy deployments (including Docker containers)
Prodigy v1.13

Prodigy v1.14
- improving CLI experience by switching to
radiclifor better error handling and type checking
- custom event hooks adding interactivity to Prodigy annotation interfaces

This is an example of a custom event hook that updates the (LLM) model in the loop.
- built-in inter-annotator agreement to facilitate data QA and calibration

Upcoming releases will include:
- introduce Structured Example feature preview which substitute a dictionary representation of annotation example for type-safe models with a clear separation of server and user annotations allowing for a more efficient storage, validation and analytics.
Prodigy v2.0
The recent updates in Prodigy were implemented with the future release of Prodigy v2.0 and Prodigy Teams in sight. For Prodigy v2.0, we are planning to upgrade the application end-to-end by:
- supporting data validation through a system of type-safe models (aka Structured Example) for representing annotation examples.
- supporting interactive, custom UI components via web components
- open-sourcing the recipes and making the core library independent of spaCy allowing for easier integrations with other NLP libraries.
- improving logging for easier debugging of custom recipes
- enhanced functionality for image and audio UI's
Keep an eye out on this thread as we'll post more updates here.
Thanks again for all of your support!