In the last few weeks we've been collecting your feedback on the v1.12 alphas (thanks for giving it a spin!) and we've been ironing out all the outstanding issues. We are excited to announce that v1.12 release candidate (v1.12.0rc2) is now available for download!
Like the alphas (and the upcoming v1.12 stable) this download is available to all v1.11x licence holders.
As mentioned in our previous post, for v1.12 we have completely refactored Prodigy internals to make the annotation flow more tractable and more customizable. Adjusting the Controller and adding new components such as Stream and Source let us deliver a number of exciting features. Here are some of the highlights:
- LLM-assisted workflows

Prodigy v1.12 offers built-in recipes for bootstrapping NER and Textcat annotations with OpenAI gpt-3.5 model. You can easily set up the workflow where the annotators curate label suggestions from the LLM, which is bound to significantly speed up the annotation process.
Apart from NER and Textcat, we also provide recipes for terminology generation which, after curation, can be used as patterns in the PatternMatcher for another type of annotation bootstrapping. See our docs for example code snippets!
The recipes support both zero-shot and few-shot prompts i.e. they allow you to provide some examples of expected output to steer the model in the right direction. Prodigy provides you with the default prompt template, but of course, custom templates are supported as well.
In order to help you make an informed the decision with respect to the optimal prompt for your purpose, Prodigy v1.12 comes with a couple of prompt engineering recipes.

You can choose between A/B style evaluation or set up a tournament between 3 or more prompts. The ab.openai.tournament uses an algorithm inspired by the Glicko ranking system to set up the duels and keep track of the best performing candidate.
Please check out our LLM guide for more details.
- The full customization of the annotation flow.

We've exposed two brand new recipe components: the task router and the session factory that let you control how tasks are distributed across annotators and what should happen when a new annotators joins the server.
We have expanded the settings for annotation overlap. Apart from full and zero overlap, you can now set partial overlap via new annotations_per_task config setting.
More importantly though you can implement a fully custom task router. For example, you could distribute tasks based on the model score or annotator's expertise. Please check out our guide to task routing for more details and ideas.
- Source-based progress estimation
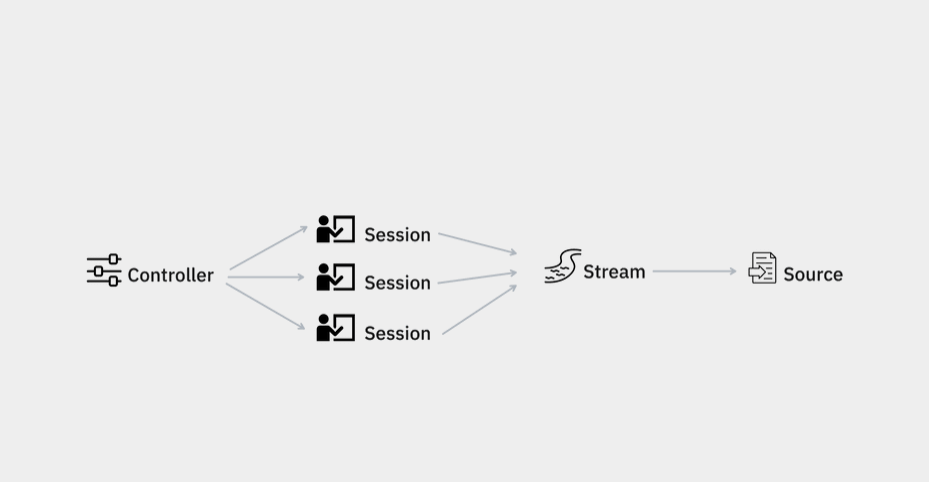
In Prodigy v1.12 we have re-implemented the internal representations of the task stream and the input source. The stream is now aware of the underlying source and how much of it has been consumed by the annotators.
This allows us to offer more reliable progress tracking for the workflows where the target number of annotations is not known upfront. In the UX, you'll notice 3 different types of progress bar: target progress (based on the set target), source progress (reflects the progress through the source object) and progress (for custom progress estimators). Since the semantics of these new progress bars is different, we recommend reading our docs on progress which explain that in detail.
We have also improved the loaders and provided a refactored get_stream utility that resolves the source type and initializes the Stream accordingly. We also added support for Parquet input files as well as a new section on the docs about deploying Prodigy.
These are the highlights,v1.12also comes with a number of smaller features, bug fixes and DX improvements. And it supports python 3.11. Please check out the full v1.12rc2 changelog for details.
As always, we are looking forward to any feedback you might have!
To install:
pip install --pre prodigy -f https://XXXX-XXXX-XXXX-XXXX@download.prodi.gy