We're looking forward to publishing more along these lines, and I'm sure there will be lots to tweak and refine in the prompts. We haven't carried out very thorough experiments with this, so please let us know what you find.
Below I've reproduced the text of my Twitter/Mastodon thread, explaining what this is and why ![]()
We've been working on new Prodigy workflows that let you use the @OpenAI API to kickstart your annotations, via zero- or few-shot learning. We've just published the first recipe, for NER annotation ![]() . Here's what, why and how.
. Here's what, why and how. ![]()
Let's say you want to do some 'traditional' NLP thing, like extracting information from text. The information you want to extract isn't on the public web — it's in this pile of documents you have sitting in front of you.
So how can models like GPT3 help? One answer is zero- or few-shot learning: you prompt the model with something like "Annotate this text for these entities", and you append your text to the prompt. This works surprisingly well! It was an in the original paper.
However, zero-shot classifiers really aren't good enough for most applications. The prompt just doesn't give you enough control over the model's behaviour.
Machine learning is basically programming by example: instead of specifying a system's behaviour with code, you (imperfectly) specify the desired behaviour with training data.
Well, zero-shot learning is like that, but without the training data. That does have some advantages — you don't have to tell it much about what you want it to do. But it's also pretty limiting. You can't tell it much about what you want it to do.
So, let's compromise. We'll pipe our data through the OpenAI API, prompting it to suggest entities for us. But instead of just shipping whatever it suggested, we're going to go through and correct its annotations. Then we'll save those out and train a much smaller supervised model.
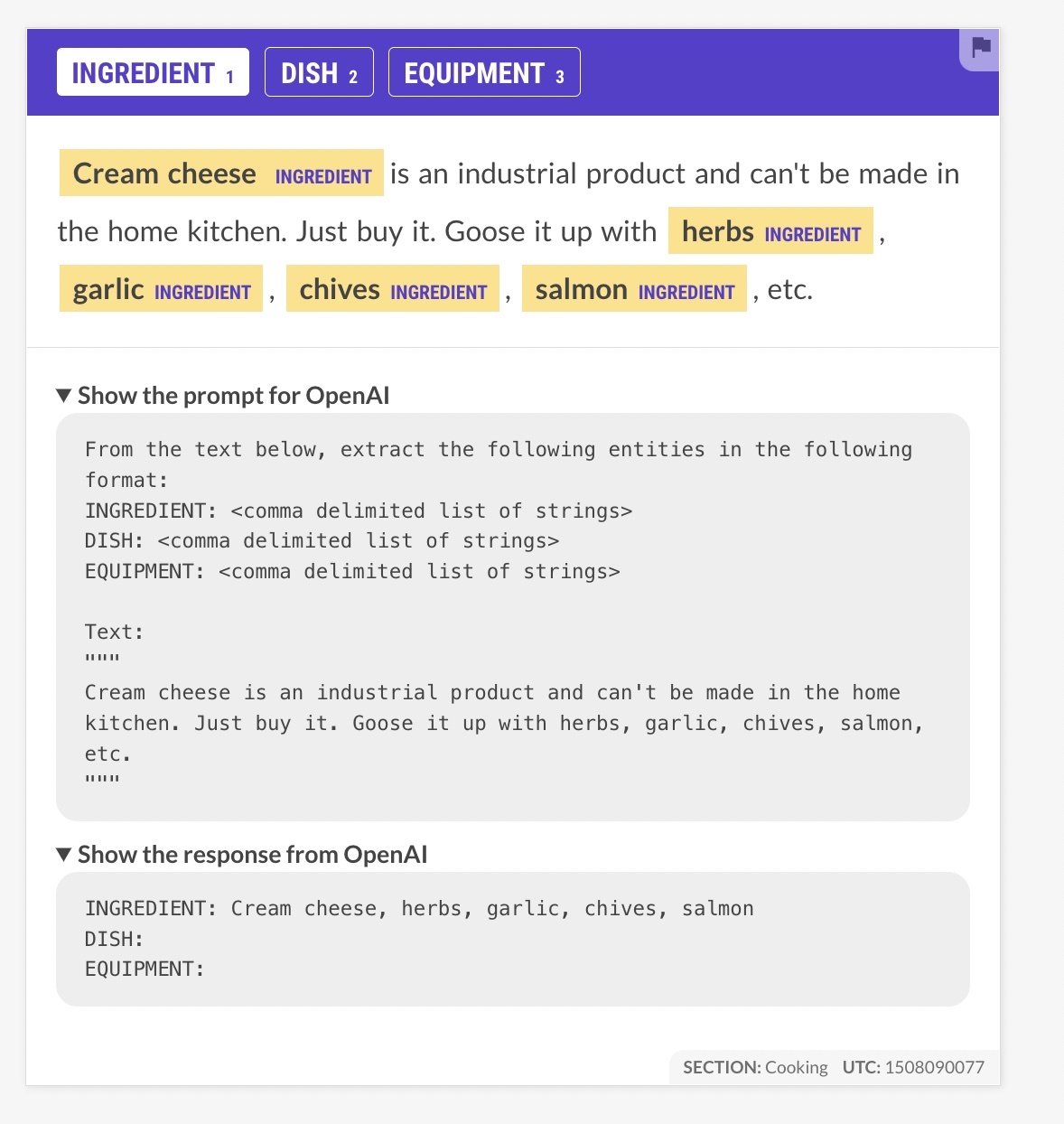
This workflow looks pretty promising from initial testing. The model provides useful suggestions for categories like "ingredient", "dish" and "equipment" just from the labels, with no examples. And the precision isn't bad — I was impressed that it avoided marking "Goose" here.
I especially like this zero-shot learning workflow because it's a great example of what we've always set out to achieve with Prodigy. Two distinct features of Prodigy are its scriptability and the ease with which you can scale down to a single-person workflow.
Modern neural networks are very sample efficient, because they use transfer learning to acquire most of their knowledge. You just need enough examples to define your problem. If annotation is mostly about problem definition, iteration is much more important than scaling.
The key to iteration speed is letting a small group of people — ideally just you! — annotate faster. That's where the scriptability comes in. Every problem is different, and we can't guess exactly what tool assistance or interface will be best. So we let you control that.
We didn't have to make any changes to Prodigy itself for this workflow — everything happens in the "recipe" script. You can build other things at least this complex for yourself, or you can start from one of our scripts and modify it according to your requirements.
If you don't have Prodigy, you can get a copy here: prodi.gy/buy. We sell Prodigy in a very old-school way, with a once-off fee for software you run yourself. There's no free download, but we're happy to issue refunds, and we can host trials for companies.