OS: Windows 10
Python: 3.7
Dist: Conda
pip installed prodigy without issues
Just got a research trial license yesterday (thanks, btw, can’t wait to show my colleagues at Northwestern!). Installed everything smoothly, default SQLite, etc. Began this training video with work-specific training (https://prodi.gy/docs/video-new-entity-type) and got the following error in conda console:
(spacy_env) C:\Users\ash9984>python -m prodigy terms.teach CAPS_terms en_core_web_lg --seeds “anxiety”
Initialising with 1 seed terms: anxiety
? Starting the web server at http://localhost:8080 …
Open the app in your browser and start annotating!
08:53:09 - Task queue depth is 1
09:02:19 - Exception when serving /give_answers
Traceback (most recent call last):
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\waitress\channel.py”, line 336, in service
task.service()
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\waitress\task.py”, line 175, in service
self.execute()
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\waitress\task.py”, line 452, in execute
app_iter = self.channel.server.application(env, start_response)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\hug\api.py”, line 423, in api_auto_instantiate
return module.hug_wsgi(*args, **kwargs)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\falcon\api.py”, line 244, in call
responder(req, resp, **params)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\hug\interface.py”, line 793, in call
raise exception
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\hug\interface.py”, line 766, in call
self.render_content(self.call_function(input_parameters), context, request, response, **kwargs)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\hug\interface.py”, line 703, in call_function
return self.interface(**parameters)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\hug\interface.py”, line 100, in call
return __hug_internal_self._function(*args, **kwargs)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\prodigy\app.py”, line 173, in give_answers
controller.receive_answers(answers, session_id=session_id)
File “cython_src\prodigy\core.pyx”, line 127, in prodigy.core.Controller.receive_answers
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\prodigy\components\db.py”, line 303, in add_examples
content=content)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\peewee.py”, line 4977, in create
inst.save(force_insert=True)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\peewee.py”, line 5170, in save
pk_from_cursor = self.insert(**field_dict).execute()
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\peewee.py”, line 3584, in execute
cursor = self._execute()
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\peewee.py”, line 2939, in _execute
return self.database.execute_sql(sql, params, self.require_commit)
File “C:\Users\ash9984\AppData\Local\Continuum\anaconda3\envs\spacy_env\lib\site-packages\peewee.py”, line 3830, in execute_sql
cursor.execute(sql, params or ())
OverflowError: Python int too large to convert to SQLite INTEGER

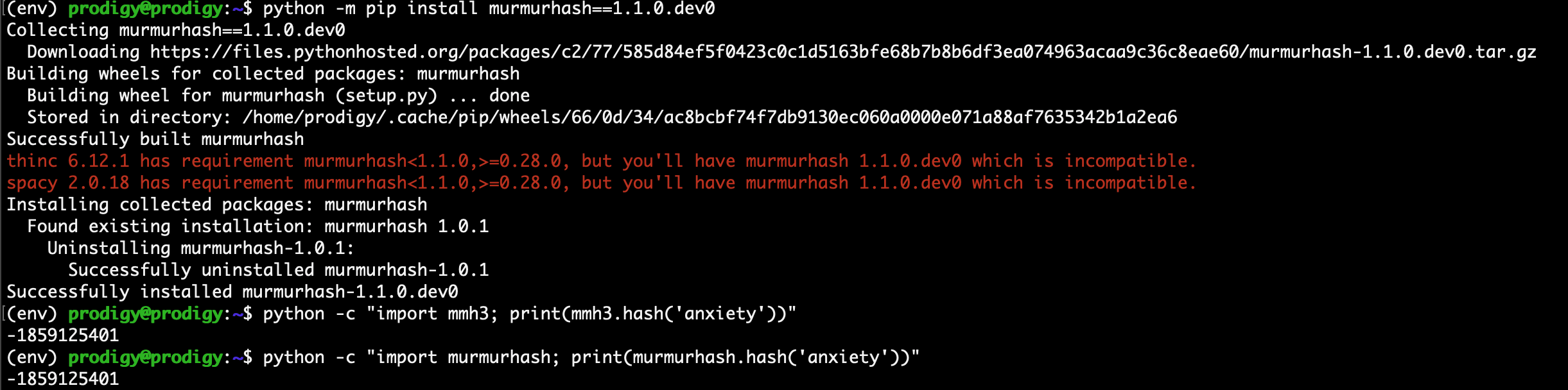
I get this error if I feed in more than 1 training term (eg, “anxiety, depression”). If I use just 1 term, server connection works but once I hit 21 session choices, I get above error in conda console and “ERROR: Couldn’t save annotations. make sure the server is running correctly.” message in training console. I’ve tried to suss out why this is happening multiple ways (variations of reject, accept, ignore, etc) and 21 seems to always trigger a disconnect from the server. Time doesn’t seem to matter, as I let minutes pass between choices.
I also reinstalled everything in a virtual environment this morning to see if that changed anything but sadly the same error persists.
Thanks in advance!!


 )
)