I am attempting to stream images to manually tag for an object detection model. I also have looped in my prototype object detection model to provide span estimates, so that the annotator just has to provide corrections.
I am running into a problem where although a batch has been loaded (and I am in the middle of annotating that batch), sporadically the software will begin to load more examples (and it doesn’t seem to stop). Because my model prediction is not lightweight (~0.5s per image), this becomes blocking, and I can no longer save my annotations.
Below is my code, for constructing the stream, and my custom recipe. Is there something I am doing wrong here?
def construct_stream():
db_cursor = my_db.find('<some-filter'>)
for x in db_cursor:
pages = x['pages']
for y in pages:
img_loc = /LOCAL/PATH/ + y
spans = estimate_annos(img_loc) # this uses existing object detection model
image_dict = {'image': img_loc, 'spans': spans}
print("YIELDING")
yield image_dict
@prodigy.recipe('object-detection')
def object_detection():
stream = construct_stream()
stream = fetch_images(stream) # convert paths to base64-encoded data URIs
return {
'stream': stream,
'update': update_db,
'db': False,
'view_id': 'image_manual',
'overlap':False
}
Thanks for the clear report. The puzzling thing here is that while 0.5s per image is fairly slow, ner.teach recipes can actually be slower per batch, if it’s searching deeply for entities of a given type. Like, sometimes I’m running recipes where only 1/100 texts are enqueued for annotation, if the entity type I’m targeting is rare. So, in theory the timing shouldn’t be such a problem.
Here’s a bit of background about how the server is working, to explain some of what you’re seeing. In order to keep the web app moving smoothly, we draw in questions in batches, and refresh the work queue behind the scenes. If you use the default batch size of 10, on first load the web app will call /get_questions and get a batch of 10 examples. Then when 5 questions are in the outbox for submission, it will call /get_questions again. If this request doesn’t return before your queue is exhausted, another request to /get_questions will be triggered, and the web app will display “Waiting for more tasks…”.
The big questions is why your recipe continues cycling through the stream. Is there anything in your update_db callback that could cause the server to block, or anything else to go wrong? I think it would be helpful to turn on the logging, using the PRODIGY_LOGGING="basic" environment variable. This will let you monitor the requests and responses from the REST API. You can also edit the prodigy/app.py source if you want to do a bit more digging yourself.
If you let me know the results from the logging, I can hopefully make some more suggestions about what could be going wrong. If you’ve customised the batch size, that would also be a useful thing to know. You could also try setting the batch size to 5 or 20, just to see if the problem gets better or worse.
Thanks! I will keep on digging myself, but I did experiment with some of the things you suggested, and so this might give you a clue.
Reducing the batch size (e.g. to 5) was partially effective. It didn’t fix the problem outright, but it made the process workable, even though annotations wouldn’t save necessarily the moment I clicked the save button, they seem to save sporadically at some point in time later.
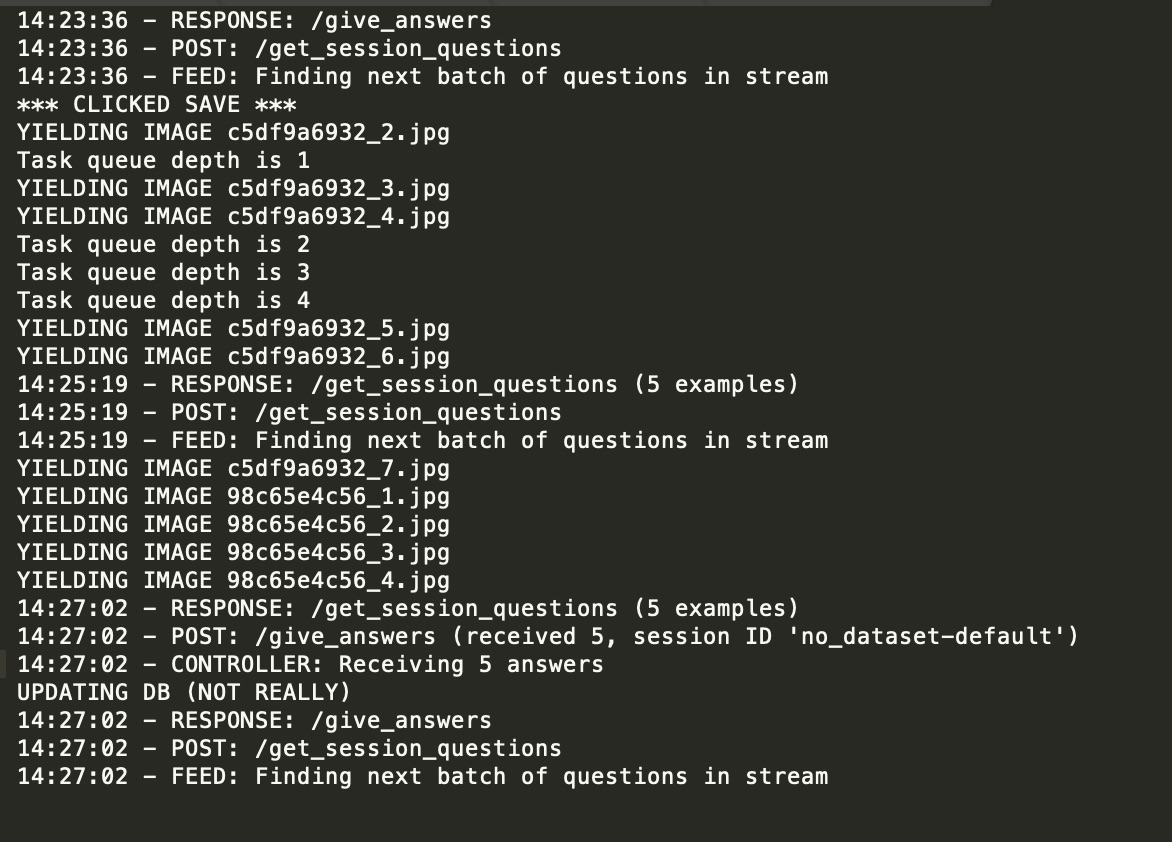
See the image of a snippet my log attached. Note: for this I reduced my update function to just a print statement, to make sure it wasn’t this blocking like you suggested. In the logs you can see “YIELDING IMAGE…” when an item of the stream is yielded and “UPDATING DB” when my update function is called.
In the log, I have manually added *** CLICKED SAVE ***, to note when I tried to save my saved annotations. After this point, I do not touch the web browser. As you can see, 10 images are yielded after this point (my batch size is only 5), and it is around 2 minutes later that my update function is called.
Let me know if there is anything else I should provide you.
And then run the web server. You’ll need to be on Prodigy v1.8+ for this. The synchronous WSGI code has these problems with blocking sometimes, when the server takes a while to respond. I’m hoping that using an asynchronous server can help a bit with this, although I’m not certain it will.
Is it possible to make your predictions faster? If you’re not doing so already, make sure you’re calling your model on batches of images, rather than one image at a time. If you’re running your model on CPU, you should also make sure that you’ve checked your thread control settings and that you’re calling into well optimised matrix multiplication routines. Have a look at top while your model is running. If it seems to be using more than 4-8 threads, you want to limit that down, usually using an environment variable like OPENMP_NUM_THREADS=8 or MKL_NUM_THREADS=8.
Actually come to think of it, if you’re not batching your images, that might explain some of the behaviour. Whenever I’m using the server with a slow prediction model, it’s always batching. This means it blocks for a while, but then it has a queue of questions ready to dispense, and so it won’t reblock later when the answers are submitted. I haven’t worked out what could be going wrong in detail, but it might be something like that?