Hello @ines,
For a given use case, I would really need to do both ner.correct and textcat.manual but I'm not able to make it work. Given complexity of document, I would rather prefer that experts only have 1 iteration across documents.
prodigy ner.correctwithtextclassificationmanual news_headlines_demo_um en_core_web_lg ./input_prodigy/demo_um/news_headlines.jsonl --label PERSON,ORG,PRODUCT,LOCATION --labeltextcat OK,NOT_OK -F ner_correctwithtextclassificationmanual.py
By the way, my text classifcation task is mutually exclusive. I don't where I can define it in my command line and in my custom script. Can you give some some guidance there?
It start as expected:
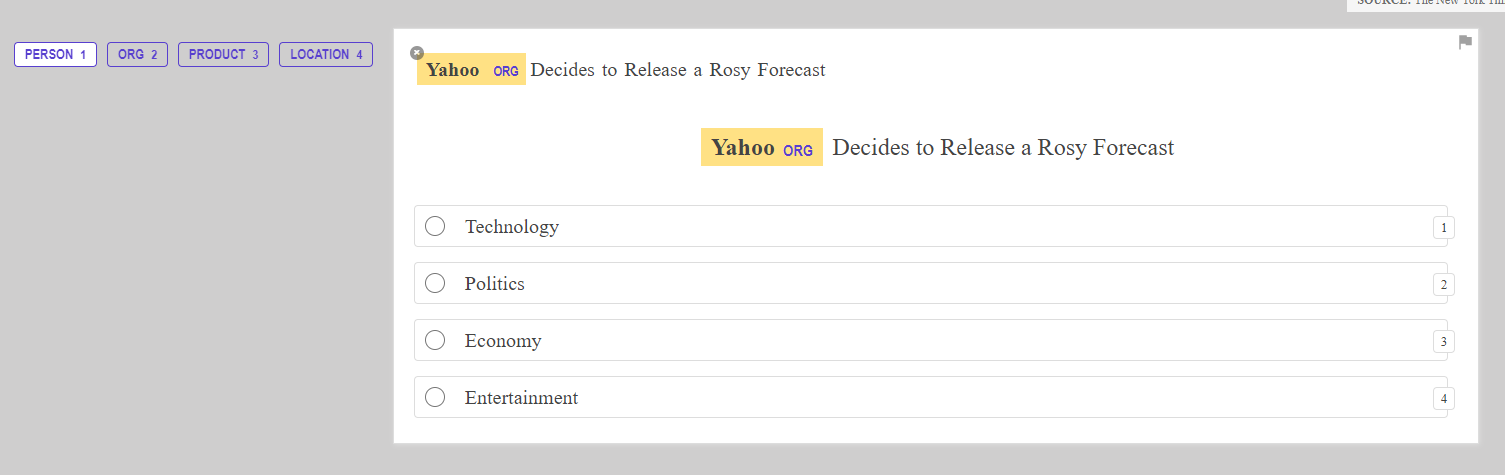
But struggle to display the task in the browser:
I have carefully read documentation about custom recipes and 'blocks' but I'm not able to make it work. I have tried multiple locations where I put label and labeltextcat but nothing works as I would like
I need 2 group of labels.
- label: for all the entities for my NER task (1st block)
- labeltextcat: categories of my textcat task (2nd block)
But I struggle where/how to use them in my custom function. Here you can find my python code regarding the custom recipe: do you have an idea what I need to change in my code?
import prodigy
from prodigy.components.loaders import JSONL
from prodigy.components.preprocess import add_tokens
from prodigy.util import split_string, set_hashes
from prodigy.util import get_labels
import spacy
import copy
from typing import List, Optional
def make_tasks(nlp, stream, labels):
"""Add a 'spans' key to each example, with predicted entities."""
# Process the stream using spaCy's nlp.pipe, which yields doc objects.
# If as_tuples=True is set, you can pass in (text, context) tuples.
texts = ((eg["text"], eg) for eg in stream)
for doc, eg in nlp.pipe(texts, as_tuples=True):
task = copy.deepcopy(eg)
spans = []
for ent in doc.ents:
# Continue if predicted entity is not selected in labels
if labels and ent.label_ not in labels:
continue
# Create span dict for the predicted entitiy
spans.append(
{
"token_start": ent.start,
"token_end": ent.end - 1,
"start": ent.start_char,
"end": ent.end_char,
"text": ent.text,
"label": ent.label_,
}
)
task["spans"] = spans
# Rehash the newly created task so that hashes reflect added data
task = set_hashes(task)
yield task
# Recipe decorator with argument annotations: (description, argument type,
# shortcut, type / converter function called on value before it's passed to
# the function). Descriptions are also shown when typing --help.
@prodigy.recipe(
"ner.correctwithtextclassificationmanual",
dataset=("The dataset to use", "positional", None, str),
spacy_model=("The base model", "positional", None, str),
source=("The source data as a JSONL file", "positional", None, str),
label=("One or more comma-separated labels", "option", "l", get_labels),
labeltextcat=("One or more comma-separated labels for text classficiation", "option", "ltextcat", get_labels),
exclude=("Names of datasets to exclude", "option", "e", split_string),
)
def ner_correctwithtextclassificationmanual(
dataset: str,
spacy_model: str,
source: str,
label: Optional[List[str]] = None,
labeltextcat: Optional[List[str]] = None,
exclude: Optional[List[str]] = None,
):
"""
Create gold-standard data by correcting a model's predictions manually.
"""
# Load the spaCy model
nlp = spacy.load(spacy_model)
# Load the stream from a JSONL file and return a generator that yields a
# dictionary for each example in the data.
stream = JSONL(source)
# Tokenize the incoming examples and add a "tokens" property to each
# example. Also handles pre-defined selected spans. Tokenization allows
# faster highlighting, because the selection can "snap" to token boundaries.
stream = add_tokens(nlp, stream)
# Add the entities predicted by the model to the tasks in the stream
stream = make_tasks(nlp, stream, label)
return {
"view_id": "blocks", # Annotation interface to use
"dataset": dataset, # Name of dataset to save annotations
"stream": stream, # Incoming stream of examples
"exclude": exclude, # List of dataset names to exclude
"config": { # Additional config settings, mostly for app UI
"lang": nlp.lang,
"labels": label,
"blocks": [
{"view_id": "ner_manual"},
{"view_id": "choice"}
]
}
}
Thanks a lot already for your time and patience 
Regards,
Cédric