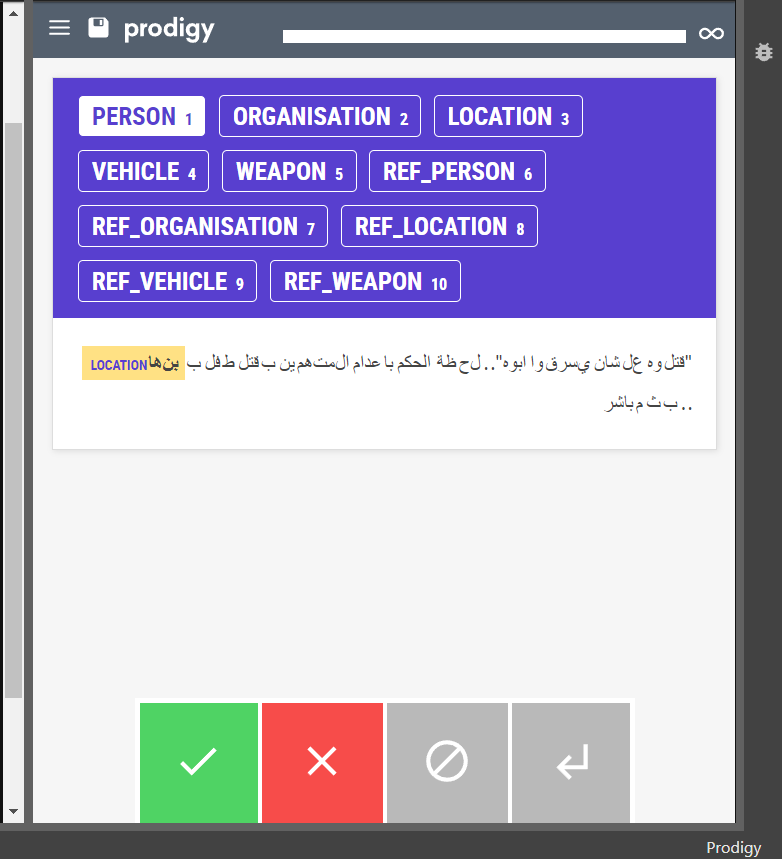
I am trying to use ner.manual with the character based annotation on Arabic.
The purpose is to tag specific characters within tokens like: entities without prepositions, or possessive pronouns, because Arabic tends to agglutinate these particles with words.
But I am facing the following issue: characters are being detached from each other, what makes the result illegible as you can see in this screenshot:
Hi! ner.manual has an option to set --highlight-chars, which lets you highlight characters instead. However, whether this makes sense to do kinda depends on the model you're looking to train later and whether you're training a character-based model or predicting token-based tags. If you're predicting token-based tags, annotating characters can be counterproductive because you'd be creating annotations that don't map to tokens your model produces, so you won't easily be able to learn from them.
If it's possible, a better approach could be to do the splitting beforehand and use custom tokenization rules or a custom tokenizer that splits subwords.
(It could also be useful to look into annotation guidelines for existing Arabic corpora to see how this is normally handled and whether they annotate the whole word or subwords for NER.)
Thank you for your reply. This result is actually produced by adding --highlight-chars .
I also tried the bert.ner.manual with a multilingual ner model. The result is better but still not enough: