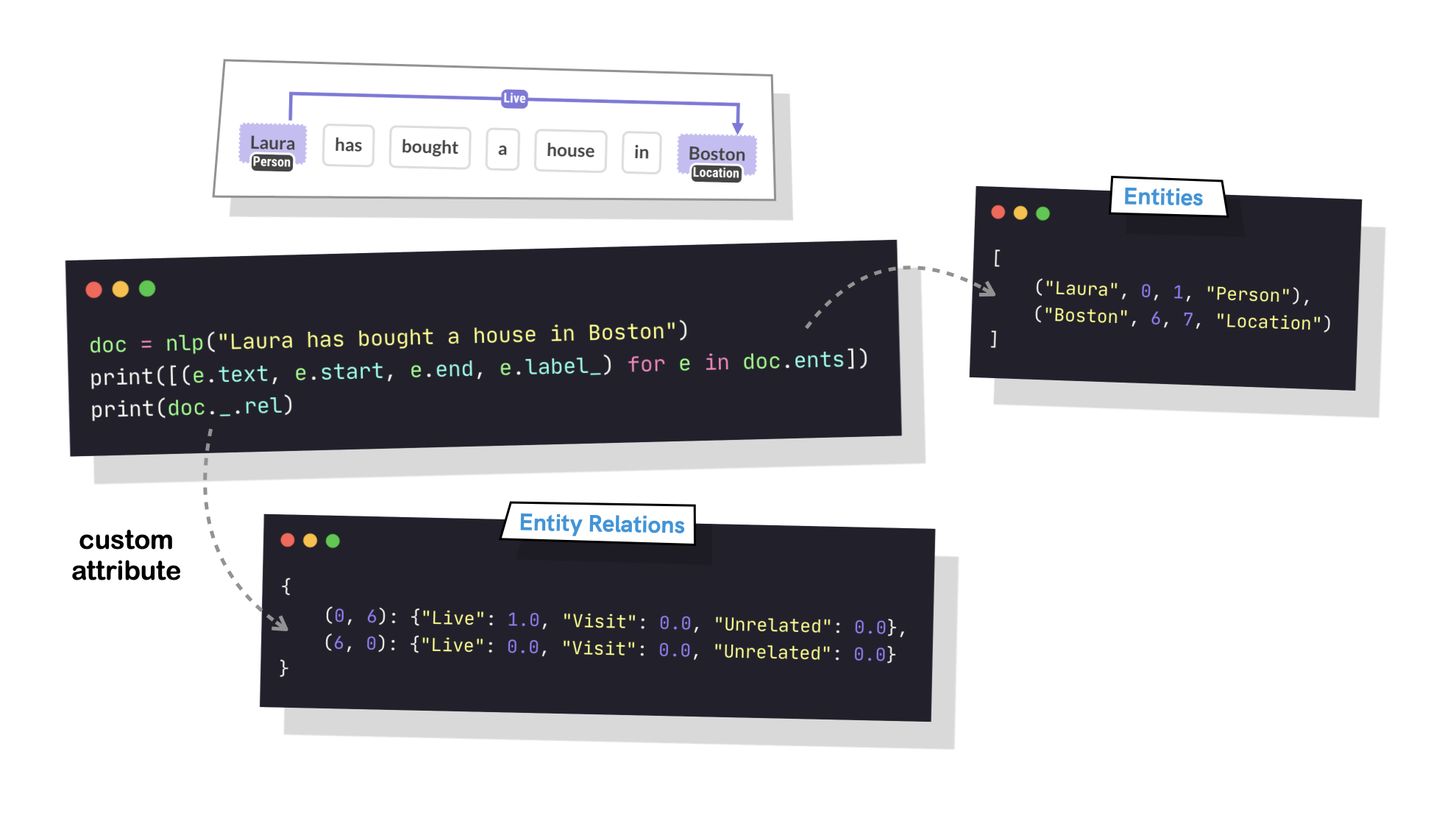
I can confirm there is still an issue. Please don't let it unresolved, I really need the relation extraction component to work on my side.
I'll give you more information about my parameters.
I'm working on Sofie's annotation.jsonl file.
I've edited the project.yml file with
script:
- "python ./scripts/parse_data_generic.py ${vars.annotations} ${vars.train_file} ${vars.dev_file} ${vars.test_file}"
My parse_data_generic.py contains :
SYMM_LABELS = ["Binds"]
DIRECTED_LABELS = ["Pos-Reg", "Neg-Reg", "No-rel", "Regulates"]
I've runned :
python -m spacy project run clean
python -m spacy project run data
python -m spacy project run train_cpu
python -m spacy project run evaluate
This is the output of train_cpu :
================================= train_cpu =================================
Running command: /usr/bin/python -m spacy train configs/rel_tok2vec.cfg --output training --paths.train data/train.spacy --paths.dev data/dev.spacy -c ./scripts/custom_functions.py
ℹ Saving to output directory: training
ℹ Using CPU
=========================== Initializing pipeline ===========================
[2023-03-27 15:34:04,066] [INFO] Set up nlp object from config
[2023-03-27 15:34:04,072] [INFO] Pipeline: ['tok2vec', 'relation_extractor']
[2023-03-27 15:34:04,074] [INFO] Created vocabulary
[2023-03-27 15:34:04,074] [INFO] Finished initializing nlp object
[2023-03-27 15:34:04,103] [INFO] Initialized pipeline components: ['tok2vec', 'relation_extractor']
✔ Initialized pipeline
============================= Training pipeline =============================
ℹ Pipeline: ['tok2vec', 'relation_extractor']
ℹ Initial learn rate: 0.001
E # LOSS TOK2VEC LOSS RELAT... REL_MICRO_P REL_MICRO_R REL_MICRO_F SCORE
--- ------ ------------ ------------- ----------- ----------- ----------- ------
0 0 0.06 0.71 21.88 35.00 26.92 0.27
220 500 0.21 4.58 63.64 35.00 45.16 0.45
625 1000 0.00 0.00 63.64 35.00 45.16 0.45
1125 1500 0.00 0.00 63.64 35.00 45.16 0.45
1625 2000 0.00 0.00 66.67 40.00 50.00 0.50
2125 2500 0.00 0.00 63.64 35.00 45.16 0.45
2625 3000 0.00 0.00 63.64 35.00 45.16 0.45
3125 3500 0.00 0.00 63.64 35.00 45.16 0.45
3625 4000 0.00 0.00 63.64 35.00 45.16 0.45
4125 4500 0.00 0.00 63.64 35.00 45.16 0.45
4625 5000 0.00 0.00 63.64 35.00 45.16 0.45
5125 5500 0.00 0.00 60.00 30.00 40.00 0.40
5625 6000 0.00 0.00 63.64 35.00 45.16 0.45
6125 6500 0.00 0.00 60.00 30.00 40.00 0.40
6625 7000 0.00 0.00 60.00 30.00 40.00 0.40
7125 7500 0.04 0.19 50.00 30.00 37.50 0.37
7625 8000 0.00 0.00 50.00 30.00 37.50 0.37
8125 8500 0.00 0.00 50.00 30.00 37.50 0.37
8625 9000 0.00 0.00 50.00 30.00 37.50 0.37
9125 9500 0.00 0.00 50.00 30.00 37.50 0.37
9625 10000 0.00 0.00 50.00 30.00 37.50 0.37
✔ Saved pipeline to output directory
training/model-last
This is the output of evaluate :
Running command: /usr/bin/python ./scripts/evaluate.py training/model-best data/test.spacy False
Random baseline:
threshold 0.00 {'rel_micro_p': '9.26', 'rel_micro_r': '100.00', 'rel_micro_f': '16.95'}
threshold 0.05 {'rel_micro_p': '9.52', 'rel_micro_r': '100.00', 'rel_micro_f': '17.39'}
threshold 0.10 {'rel_micro_p': '9.28', 'rel_micro_r': '90.00', 'rel_micro_f': '16.82'}
threshold 0.20 {'rel_micro_p': '8.79', 'rel_micro_r': '80.00', 'rel_micro_f': '15.84'}
threshold 0.30 {'rel_micro_p': '9.88', 'rel_micro_r': '80.00', 'rel_micro_f': '17.58'}
threshold 0.40 {'rel_micro_p': '11.94', 'rel_micro_r': '80.00', 'rel_micro_f': '20.78'}
threshold 0.50 {'rel_micro_p': '12.50', 'rel_micro_r': '70.00', 'rel_micro_f': '21.21'}
threshold 0.60 {'rel_micro_p': '6.82', 'rel_micro_r': '30.00', 'rel_micro_f': '11.11'}
threshold 0.70 {'rel_micro_p': '5.88', 'rel_micro_r': '20.00', 'rel_micro_f': '9.09'}
threshold 0.80 {'rel_micro_p': '5.26', 'rel_micro_r': '10.00', 'rel_micro_f': '6.90'}
threshold 0.90 {'rel_micro_p': '0.00', 'rel_micro_r': '0.00', 'rel_micro_f': '0.00'}
threshold 0.99 {'rel_micro_p': '0.00', 'rel_micro_r': '0.00', 'rel_micro_f': '0.00'}
threshold 1.00 {'rel_micro_p': '0.00', 'rel_micro_r': '0.00', 'rel_micro_f': '0.00'}
Results of the trained model:
threshold 0.00 {'rel_micro_p': '9.26', 'rel_micro_r': '100.00', 'rel_micro_f': '16.95'}
threshold 0.05 {'rel_micro_p': '22.86', 'rel_micro_r': '80.00', 'rel_micro_f': '35.56'}
threshold 0.10 {'rel_micro_p': '25.81', 'rel_micro_r': '80.00', 'rel_micro_f': '39.02'}
threshold 0.20 {'rel_micro_p': '34.78', 'rel_micro_r': '80.00', 'rel_micro_f': '48.48'}
threshold 0.30 {'rel_micro_p': '38.10', 'rel_micro_r': '80.00', 'rel_micro_f': '51.61'}
threshold 0.40 {'rel_micro_p': '41.18', 'rel_micro_r': '70.00', 'rel_micro_f': '51.85'}
threshold 0.50 {'rel_micro_p': '40.00', 'rel_micro_r': '60.00', 'rel_micro_f': '48.00'}
threshold 0.60 {'rel_micro_p': '54.55', 'rel_micro_r': '60.00', 'rel_micro_f': '57.14'}
threshold 0.70 {'rel_micro_p': '66.67', 'rel_micro_r': '60.00', 'rel_micro_f': '63.16'}
threshold 0.80 {'rel_micro_p': '75.00', 'rel_micro_r': '60.00', 'rel_micro_f': '66.67'}
threshold 0.90 {'rel_micro_p': '80.00', 'rel_micro_r': '40.00', 'rel_micro_f': '53.33'}
threshold 0.99 {'rel_micro_p': '100.00', 'rel_micro_r': '10.00', 'rel_micro_f': '18.18'}
threshold 1.00 {'rel_micro_p': '0.00', 'rel_micro_r': '0.00', 'rel_micro_f': '0.00'}
So it looks like the model was correctly generated, right ?
But now I want to use it. So that is why I'm trying to load it in the test_project_rel.py file. I've used a long line of text from the training set, to maximize the chances of recognizing something. What I'm doing is :
model = "training/model-best"
text = "Transcriptional regulation of lysosomal acid lipase in differentiating monocytes is mediated by transcription factors Sp1 and AP-2. \nHuman lysosomal acid lipase (LAL) is a hydrolase required for the cleavage of cholesteryl esters and triglycerides derived from plasma lipoproteins."
nlp = spacy.load(model)
doc = nlp(text)
for ent in doc.ents:
print(ent.text, ent.start_char, ent.end_char, ent.label_)
for rel in doc._.rel:
print(rel)
And I obtain 
ℹ Could not determine any instances in doc - returning doc as is.
Not even named entities are recognized. It is exactly the same with my own annotations.jsonl file (and my named entities and relations labels). Still, when I'm training a regular NER model outside the relation component, everything runs fine.
My team really need this component working, could you please explain to me what is the remaining issue ?
Thank you very much.