I am not sure that its loading from a Python package, what I am sure in is that I packaged it and installed but on load the custom code is not executed and I don't know what I have to do to make it executed
If you call spacy.load, the argument can either be a path, shortcut link or name of an installed package. So if you pass in the name of an installed package and it exists, it will be loaded.
To load from an installed package, you can also import the package directly and call its load method. That's also what spaCy does under the hood. For example:
import en_custom_model
nlp = en_custom_model.load()
If your load() function isn't executed, that likely means that whatever it's loading there is not actually your custom package, or that the package isn't up to date. Maybe you have a symlink in spacy/data or another installed package that is shadowing it?
Yes, that's exactly what I had, thank you! I changed the name and it worked! <3
1 Like
@ines I run into the same issue with Spacy3 when trying to load the trained model with a custom tokenizer, I added "customize_tokenizer" function as a callback in the [initialize.before_init] in config file, and a callback in [nlp.before_creation] to add CutomTokenizer to Language.Defaults.create_tokenizer,
import spacy
from spacy.util import registry
from spacy_custom_tokenizer import CustomTokenizer
@registry.callbacks("customize_tokenizer")
def make_customize_tokenizer():
def customize_tokenizer(nlp):
nlp.tokenizer = CustomTokenizer(nlp.vocab)
return customize_tokenizer
@spacy.registry.callbacks("customize_language_data")
def create_callback():
def customize_language_data(lang_cls):
lang_cls.Defaults.create_tokenizer = CustomTokenizer
return lang_cls
return customize_language_data
But still getting the following issue,
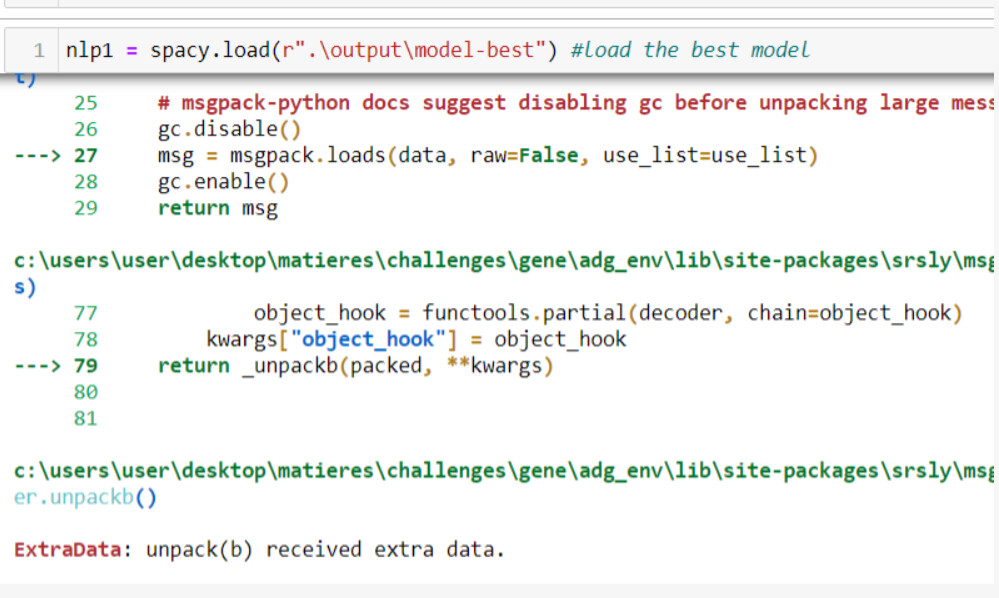
I am just answering my question if anyone runs into the same issue I got with Spacy3, you only need to add the custom tokenizer to registry.tokenizers
@spacy.registry.tokenizers("custom_tokenizer")
def create_custom_tokenizer():
def create_tokenizer(nlp):
return CustomTokenizer(nlp.vocab)
return create_tokenizer
and overwrite default spacy's tokenizer in config.cfg file: '''tokenizer = {"@tokenizers":"custom_tokenizer"}'''
1 Like