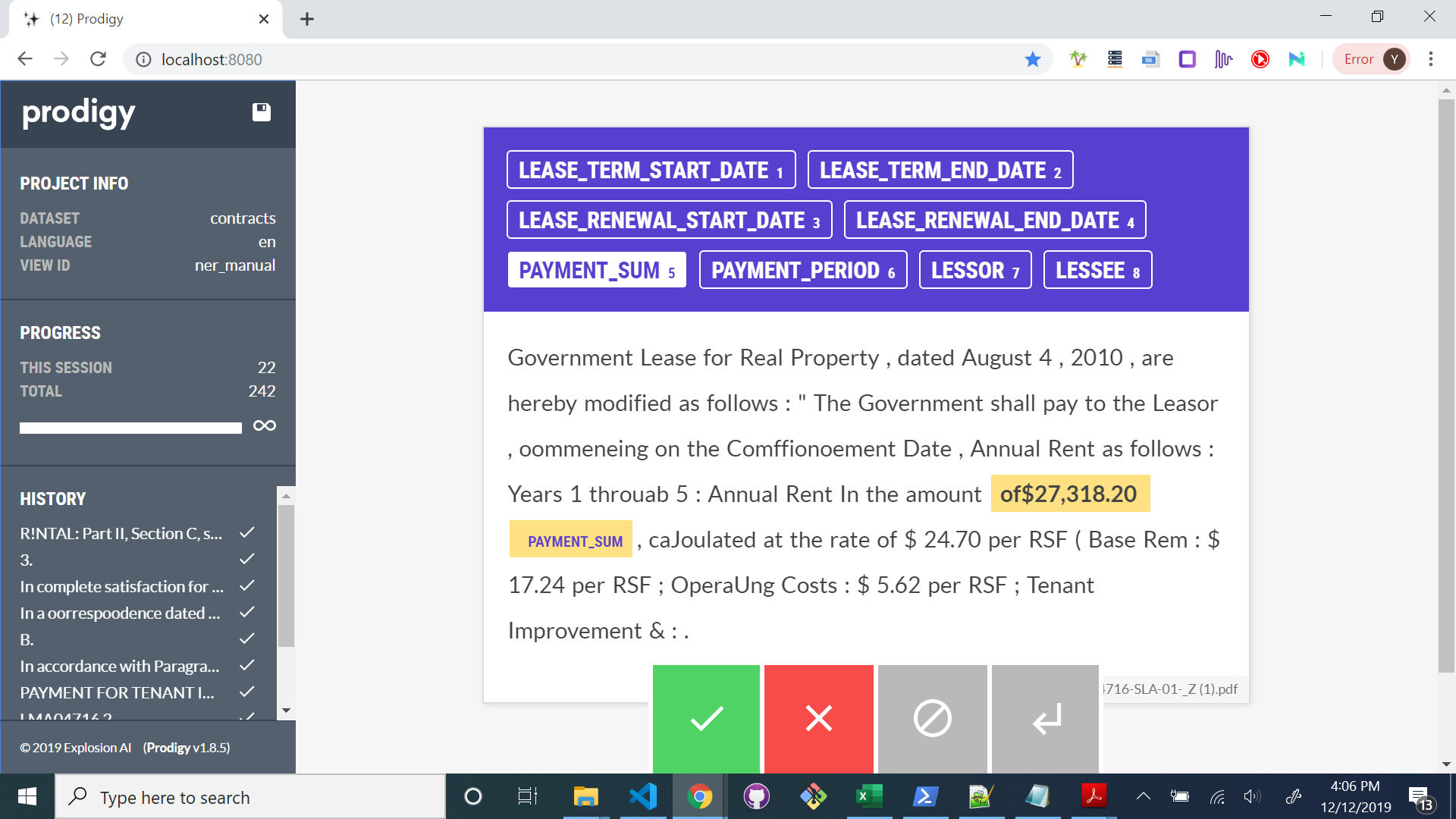
i am not sure how i can just label the money amount without the mistaken prefix.
what about manually correcting the text back in the jsonl file? is that too clunky of an approach?
I'd recommend modifying your tokenizer so that of$23,318.20 get tokenized to ["of", "$", "23,318.20"] which is not the case with the default english tokenizer.
from spacy.util import compile_infix_regex
def create_custom_tokenizer(nlp):
infixes = nlp.Defaults.infixes + (
r"[$]",
)
tokenizer = nlp.Defaults.create_tokenizer(nlp)
tokenizer.infix_finditer = compile_infix_regex(infixes).finditer
return tokenizer
nlp.tokenizer = create_custom_tokenizer(nlp)
assert [t for t in nlp('of$23,318.20')] == ["of", "$", "23,318.20"]
Then you can nlp.to_disk and use that model with the custom tokenizer.
Note I am not from Explosion AI so don't take this as an "official answer".
Yes, that's exactly what I would have recommended. If the entities you want to extract do not map to valid token boundaries, your model wouldn't be learning anything from those annotations anyways, even if you were able to create them and highlight partial entities. So if this is a common occurrence, you want to make sure that your tokenization rules produce the tokens you need.