During the normal ner operation, a jsonl file was put into the ner operation of the bert model, and suddenly there was a bug.
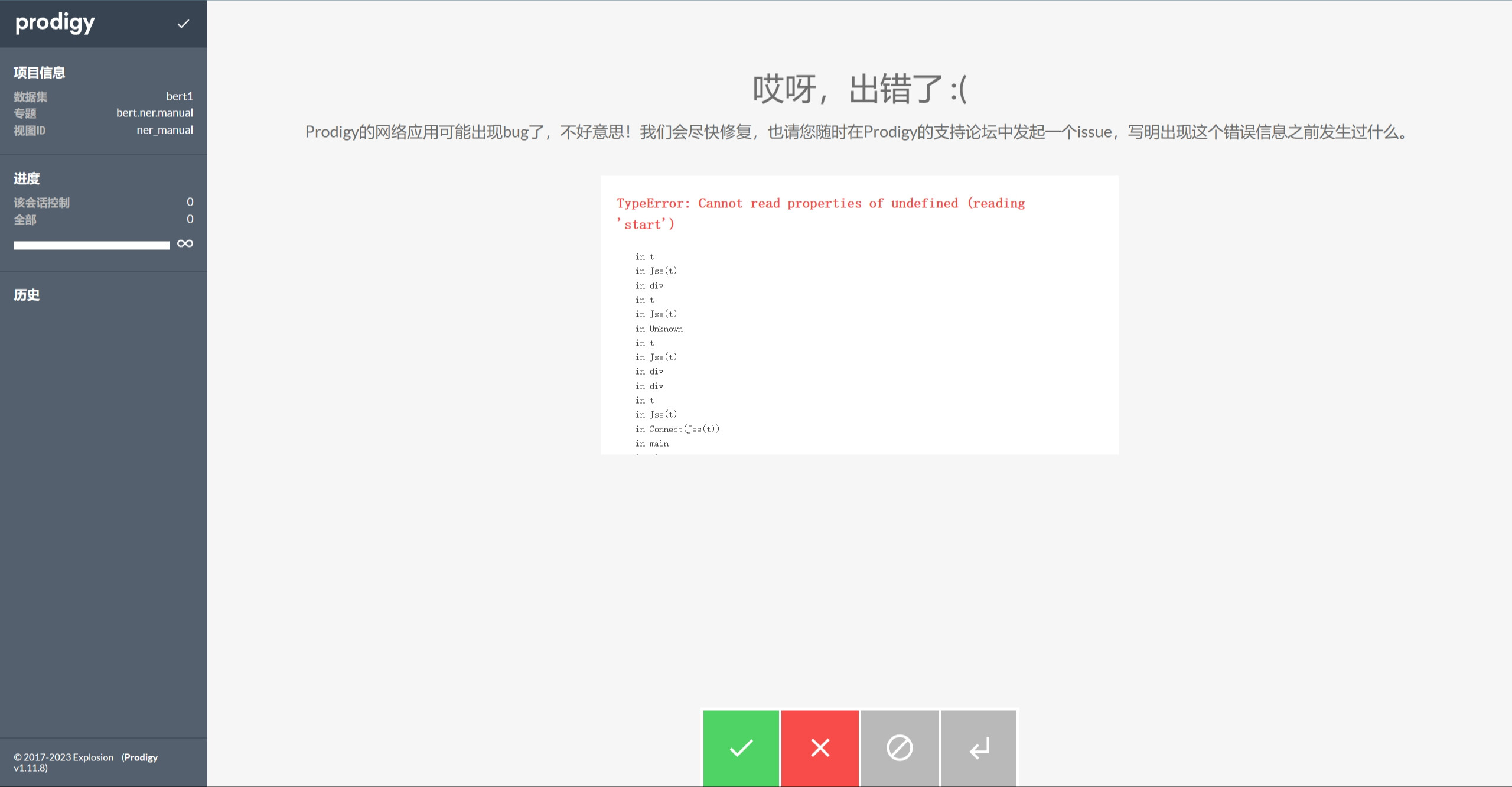
Per your earlier message, I think misaligned tokenization is the problem, not a bug.
In fact, we've had that same error message (reading 'start') from a similar problem:
But I think this indicates the problem could be character-based tokenization (like in Chinese) versus token-based tokenization. You may want to set character-based tokenization in your Prodigy annotations. The docs describe this:
The
ner.manualrecipe also lets you set a--highlight-charsflag to allow highlighting individual characters instead of only tokens. This will only store the character offsets of your annotation and won’t add a"tokens"property to the saved task.
When using character-based highlighting, annotation may be slower and there’s no guarantee that the spans you annotate map to actual tokens later on. If your goal is to train a named entity recognizer, you should consider using the same tokenizer during annotation, to make sure that your data can be used. Also see the section on efficient annotation for transformers if you’re training a transformer-based model (e.g. BERT) with subword tokenization.