I’m currently working on a classification project with approximately 850 classes and 240k training samples. Currently textcat.batch-train takes over 7 hours per training iteration and doesn’t appear to take advantage of the 24 cores available on my machine. Are recipes multiprocessing capable? If so how do I enable this feature?
The most expensive part of training should be in the matrix multiplications, which numpy should be delegating to a BLAS library. It’s possible something hasn’t been compiled with proper optimisations for your machine, but my guess is this is more likely to be an issue with the hyper-parameters.
Some questions to help figure this out:
-
If you’re using Linux, are you able to watch the process in
perf top? If so, what function does it seem to spend most time within? -
How long are your texts?
-
Have you tried increasing the batch size? The default of 10 is tuned for low-data use-cases, as our default assumption is that the data was manually annotated. If you increase the batch size to 32, do you get better CPU utilisation?
Finally, 850 labels is actually more than I’ve trained spaCy’s textcat with. It’s possible I’m making an expensive loop somewhere, so there might be a simple optimisation I can make within spaCy. I’ll have a look.
Matthew,
Thanks for a quick reply.
The most expensive part of training should be in the matrix multiplications, which numpy should be delegating to a BLAS library. It’s possible something hasn’t been compiled with proper optimisations for your machine,
I'm using the Intel MKL library and scipy.show_config() indicates that it has been built using MKL. Additionally gensim.models.word2vec.FAST_VERSION == 1.
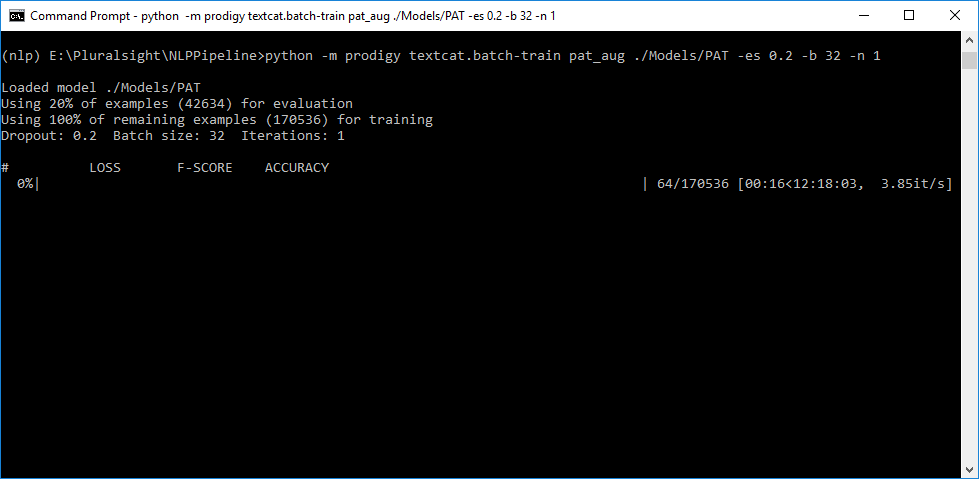
Here is a snapshot of what I'm running. Data was loaded using db-in. Classes are imbalanced with a minimum of 6 positive examples and a maximum of 280. Classes are mutually exclusive and an equal number of negative examples were randomly generated for each class based on the number of positive examples.
If you’re using Linux, are you able to watch the process in perf top? If so, what function does it seem to spend most time within?
I'm running this on Windows 10 and the Windows Resource Monitor / Task Manager only shows a single python process.
How long are your texts?
I'm trying to classify product descriptions.
Word Counts
Min: 53
Mean: 692
Max: 2004
Have you tried increasing the batch size? The default of 10 is tuned for low-data use-cases, as our default assumption is that the data was manually annotated. If you increase the batch size to 32, do you get better CPU utilisation?
I've tried a batch size of 10, 32, 64, 128, 256. While total time goes down with an increased batch size, I don't think CPU utilization is better. Bigger batch size does result in slightly higher it/s, but nothing drastic.