Thank you, @dave-espinosa!
First off, huge thank you for your wonderful reproducible example. I was able to diagnose the problem very quickly. I can't thank you enough for the time you put into your questions that helps us to more quickly help you.
It looks like the default behavior is that pattern labels override pre-existing labels. I didn't realize this either until I went into the code base. I found a related post:
Ines mentions that this is intended:
If you run a recipe like
ner.manualwith patterns and examples with pre-defined"spans", those spans will be overwritten. That's expected – otherwise, the results would be pretty confusing, you'd constantly have to resolve overlaps between existing spans and matches etc.
The post also gave me an idea to programmatically create a new dataset that uses the pre-existing annotations and also appends the patterns using PatternMatcher.
Then use that new dataset either for training or again in ner.manual to correct.
Here's the script:
from prodigy.components.db import connect
from prodigy.models.matcher import PatternMatcher
import spacy
# spacy model
nlp = spacy.blank("en")
# patterns file
patterns = "testpattern.jsonl"
db = connect()
# existing annotations
examples = db.get_dataset("labeled_data1")
# create pattern_matcher and load patterns from file
pattern_matcher = PatternMatcher(nlp, combine_matches=True, all_examples=True)
pattern_matcher = pattern_matcher.from_disk(patterns)
# assign known patterns
examples_patterns = (eg for _, eg in pattern_matcher(examples))
# loop to combine existing annotations with patterns
combined_examples = []
for eg,eg_p in zip(examples,examples_patterns):
# need logic to dedup overlapping spans (both pre-existing and pattern)
seen_tokens = set()
for entity_match in eg["spans"]:
# put all entity matches into seen
seen_tokens.update(range(entity_match["start"], entity_match["end"]))
for pattern_match in eg_p["spans"]:
if pattern_match["start"] not in seen_tokens and pattern_match["end"] - 1 not in seen_tokens:
eg["spans"].append(pattern_match)
seen_tokens.update(range(pattern_match["start"], pattern_match["end"]))
combined_examples.append(eg)
db.add_dataset("labeled_data2") # create a new dataset for combined examples
db.add_examples(combined_examples, ["labeled_data2"]) # load combined examples into this dataset
One thing that was tricky was that I realized I needed to account for any overlapping (double counting) spans that were in the pre-existing and rules. Hence I tried to create logic similar to spaCy's filter_spans that checks whether the span has been included. I couldn't robustly test but it seems to do the trick.
Now try to run that code to create a new dataset labeled_data2 (it has the original labels plus the patterns).
Then rerun ner.manual with dataset:labeled_data2 and without the patterns (since that code puts in the patterns) so now see both the patterns and the original labels:
python -m prodigy ner.manual labeled_data3 blank:en dataset:labeled_data2 --label SKILL
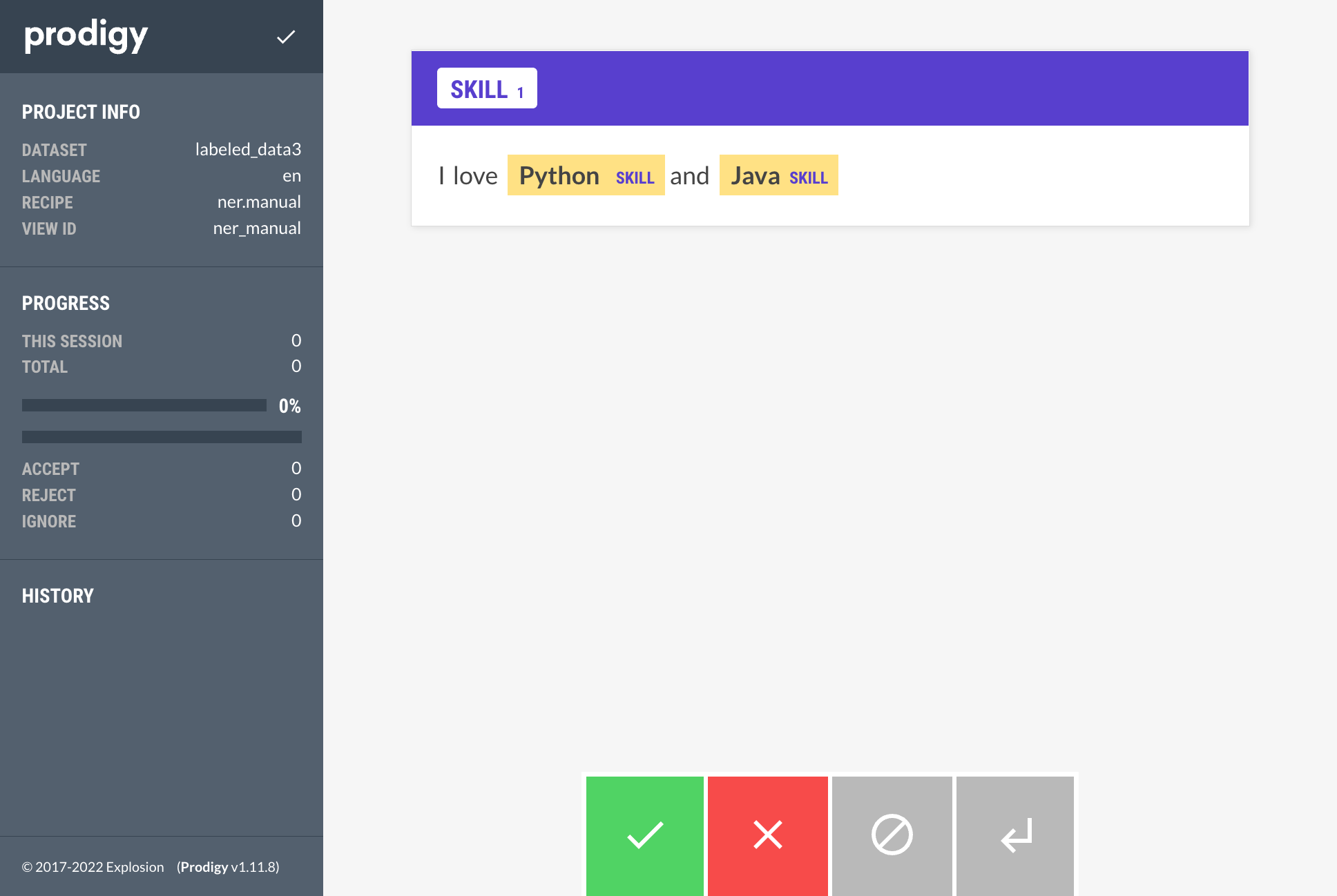
Also you can run print-dataset to get a faster preview:
python -m prodigy print-dataset labeled_data2

Hope this helps!