Hi! A similar question came up in this thread a while ago, so re-sharing the response with solutions:
Given your labels and complexity, I think it could be helpful to break down the task and focus on a subset at a time, e.g. SENTIMENT or EXTERNAL, and combine the data later on. This means the UI can be simpler to navigate and the human annotator doesn't have to mentally "iterate" over all categories for each example (also illustrated here).
If you haven't seen it yet, this section in our case study with S&P Global illustrates a similar approach, making the overall annotation 10 times faster as a result: How S&P Global is making markets more transparent with NLP, spaCy and Prodigy · Explosion
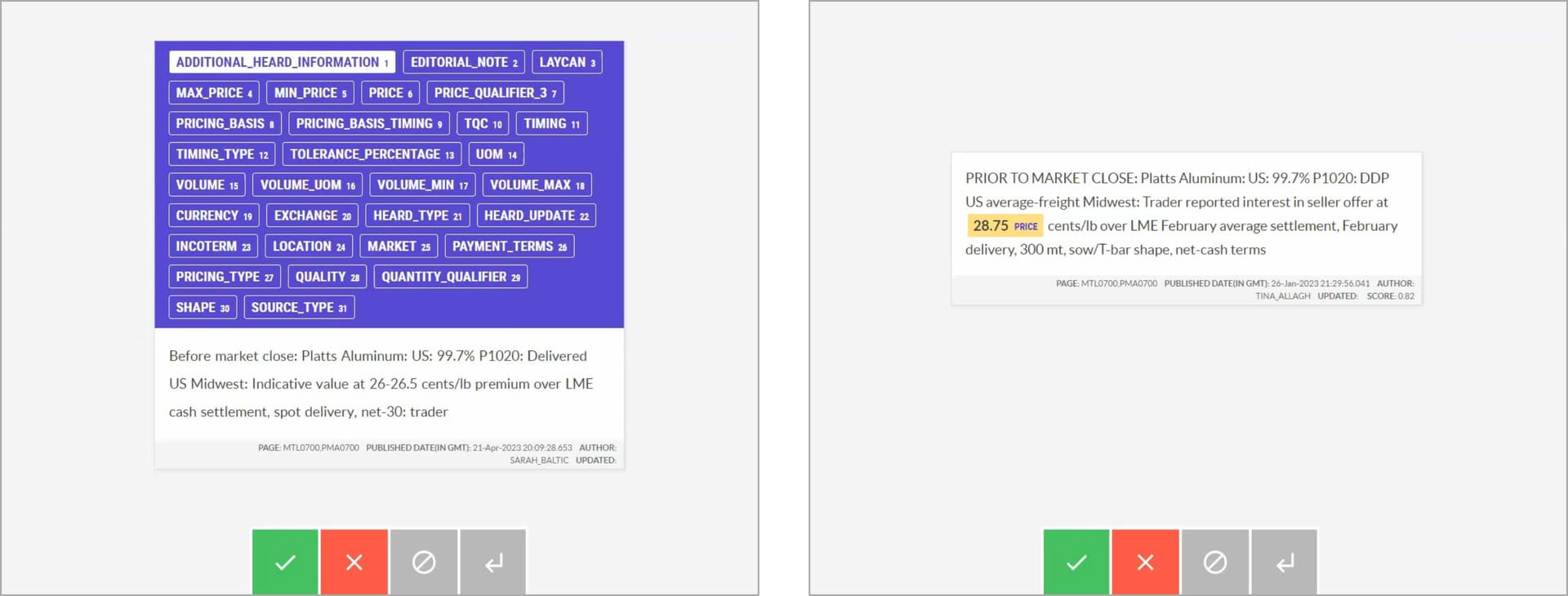
However, the cognitive load from having to consider this many attributes at the same time made the process incredibly tedious and too slow to be practical. [...] So the team tried something else: focusing on a single label at a time and making multiple passes over the heards data, once per attribute. Although this sounded like more work at first, it drastically sped up annotation time by over 10×.