@ines,
So, I have been trying out all your suggestions and the rule-based matcher is working for the most part, at least for MACADDRESS. I have it annotated examples in Spacy and am verifying them on Prodigy.
I am finding something happening that I cannot seem to explain through my efforts. The regex rule-based matching for IPADDRESS is not working via Spacy and is all over the place. I have taken apart my code and tested it line by line in the interpreter, including the regex separately online to see if there is any problem with the regex, but to no avail. Let me try to provide you with screenshots and see if it shows what I am talking about.
Python Interpreter Regex Match:
Regex Matcher:
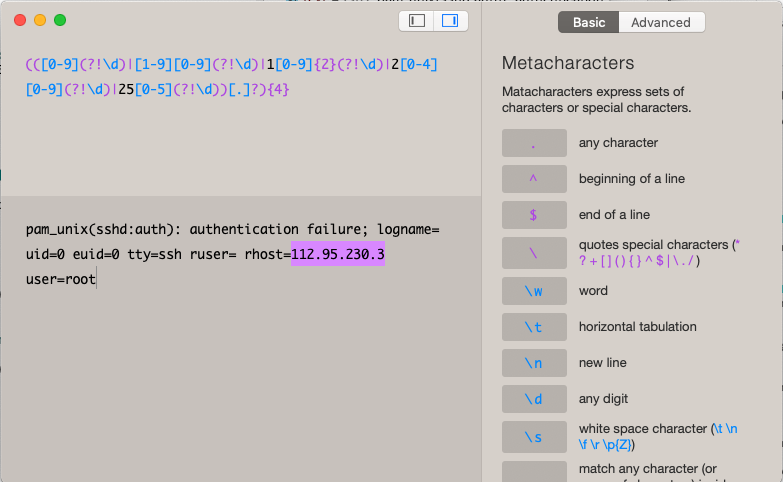
Spacy Rule-Based Annotation:
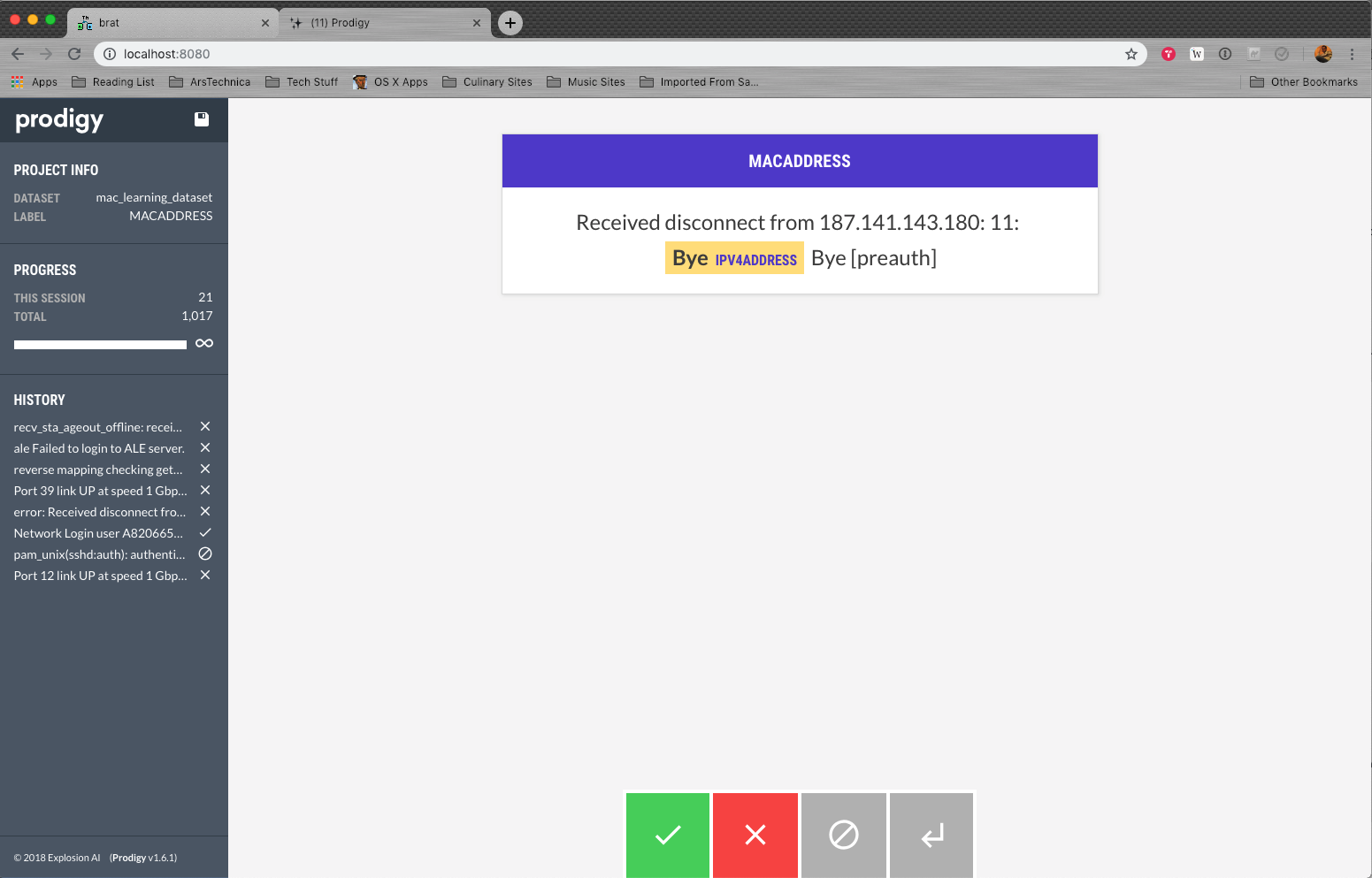
There is an IPADDRESS right there in the example that it has not annotated. A jsonl example is below.
{"text": "error: Received disconnect from 103.99.0.122: 14: No more user authentication methods available. [preauth]", "spans": [{"start": 46, "end": 49, "text": "14:", "label": "IPV4ADDRESS"}, {"start": 50, "end": 52, "text": "No", "label": "IPV4ADDRESS"}, {"start": 86, "end": 96, "text": "available.", "label": "IPV4ADDRESS"}, {"start": 97, "end": 98, "text": "[", "label": "IPV4ADDRESS"}], "tokens": [{"text": "error:", "start": 0, "end": 6, "id": 0}, {"text": "Received", "start": 7, "end": 15, "id": 1}, {"text": "disconnect", "start": 16, "end": 26, "id": 2}, {"text": "from", "start": 27, "end": 31, "id": 3}, {"text": "103.99.0.122:", "start": 32, "end": 45, "id": 4}, {"text": "14:", "start": 46, "end": 49, "id": 5}, {"text": "No", "start": 50, "end": 52, "id": 6}, {"text": "more", "start": 53, "end": 57, "id": 7}, {"text": "user", "start": 58, "end": 62, "id": 8}, {"text": "authentication", "start": 63, "end": 77, "id": 9}, {"text": "methods", "start": 78, "end": 85, "id": 10}, {"text": "available.", "start": 86, "end": 96, "id": 11}, {"text": "[", "start": 97, "end": 98, "id": 12}, {"text": "preauth", "start": 98, "end": 105, "id": 13}, {"text": "]", "start": 105, "end": 106, "id": 14}]}
There are many more examples like this. Actually, it is extremely unlikely that it got anything right with the IPADDRESS regex. I don’t seem to understand why the same regex works outside of the Spacy rule-based matcher, but not inside it. Also, it is weird that it seems to be NER tagging regular english words with the label, as in the example.
Regex Patterns:
REGEX_PATTERNS = [(URL_PATTERN, 'URL'),
(MAC_PATTERN, 'MACADDRESS'),
(IPV4_PATTERN, 'IPV4ADDRESS'),
(IPV6_PATTERN, 'IPV6ADDRESS'),
(PROCESS_PATTERN, 'PROCESS'),
(FILE_PATTERN, 'FILE/RESOURCE'),
(HYPHENATED_PATTERN, 'HYPHENATED-ENTITY'),
(KEY_VALUE_PATTERN, 'KEY-VALUE PAIR')
]
Regex-Matcher Code:
class RegexMatcher(object):
def __init__(self, expression, label):
self.regex_patterns = defaultdict()
self.regex_patterns[label] = re.compile(expression, re.UNICODE)
def __call__(self, document):
task = {}
for label, expression in self.regex_patterns.items():
for match in re.finditer(expression, document.text): # find match in example text
# task = copy.deepcopy(eg) # match found – copy the example
start, end = match.span()
# get matched indices
task["spans"] = [{"start": start, "end": end, "text": match.group(), "label": label}] # label match
yield 0.5, task # (score, example) tuples
def add_regex_patterns(self, expression, label):
self.regex_patterns[label] = re.compile(expression, re.UNICODE)
def update(self, examples):
# this is normally used for updating the model, but we're just
# going to do nothing here and return 0, which will be added to
# the loss returned by the model's update() method
return 0
def get_regex_patterns(self):
return self.regex_patterns
Rule-Based Matcher Code:
def convert_char_span_to_token_idx(doc, entities=None):
token_starts = {token.idx: token.i for token in doc}
token_ends = {token.idx+len(token): token.i for token in doc}
for start_char, end_char, label in entities:
# Get the token start and end indices, which in our case should be the same,
# since we normally do not have multi-token spans
token_start_index = token_starts.get(start_char)
token_end_index = token_ends.get(end_char)
if token_start_index is not None and token_end_index is not None:
if token_start_index == token_end_index:
# We have a single token that matches
return token_start_index, token_end_index
else:
# TODO - handle multi-token spans later
pass
elif token_start_index is None or token_end_index is None:
return None, None
else:
pass
def custom_entity_matcher(doc):
# This function will be run automatically when you call nlp
# on a string of text. It receives the doc object and lets
# you write to it – e.g. to the doc.ents or a custom attribute
regex_matcher = RegexMatcher(REGEX_PATTERNS[1][0], REGEX_PATTERNS[1][1])
regex_matcher.add_regex_patterns(REGEX_PATTERNS[2][0], REGEX_PATTERNS[2][1])
regex_matches = regex_matcher(doc)
for match in regex_matches:
# Create a new Span object from the doc, the start token
# and the end token index
char_start_offset = match[1]['spans'][0]['start']
char_end_offset = match[1]['spans'][0]['end']
entity = (char_start_offset, char_end_offset, match[1]['spans'][0]['label'])
if entity is None:
continue
elif doc is None:
continue
else:
token_start, token_end = convert_char_span_to_token_idx(doc, [entity])
if token_start is None or token_end is None:
continue
span = \
Span(doc, token_start, token_end, label=doc.vocab.strings[match[1]['spans'][0]['label']])
# Overwrite the doc.ents and add your new entity span
doc.ents = list(doc.ents) + [span]
return doc
I am just not able to figure out if this is a general regex issue (which it does not seem to be, by my external tests) or a Spacy rule-matcher issue. Any inputs are greatly appreciated. Till then, I can at least train it on the other label.



